139. 单词拆分
Medium
思路
这道之前已经提交过一次,但是现在碰到,又是没啥印象,要重新分析。这也是我做刷题笔记的理由之一:加深记忆、方便review
分析题目:
- 我先想到的方法是,使用一个指针
i去遍历字符串,当\([0,i]\)的字串在单词列表中时,就把字串删除,继续遍历剩余部分
显然是有问题的
case: s="catsdog" words=["cat","cats","dog"] 当遍历到cat删除之后,剩余部分为sdog,无法匹配任何单词
- 虽然上面的想法不对,但是我们可以发现,我们一开始从
words中去选择是有多种可能性的,比如,上面的例子中,我们可以选cat也可以选cats,当然也可以选dog,只不过这种情况是不匹配的 - 当我们选定了一个
word了之后,我们在剩下的字符串中也做相同的操作,直到s全部匹配完。如果都能找到对应的word说明匹配成功,否则匹配失败 如下图: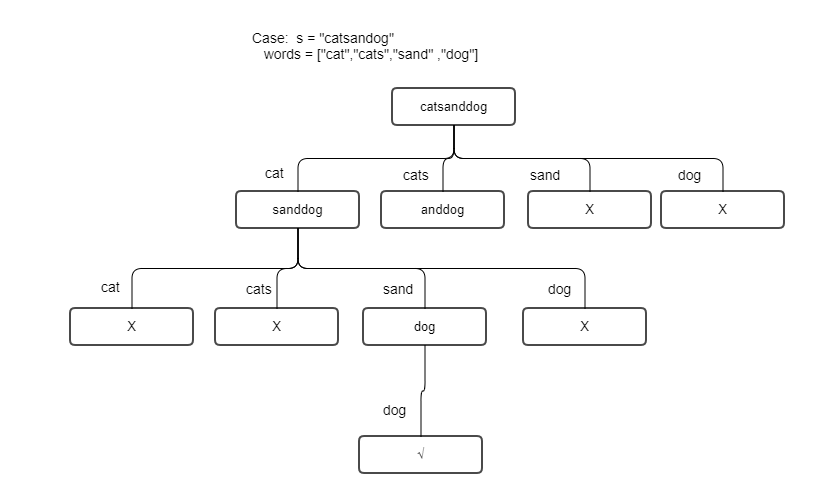
- 显然是一个树状结构,使用DFS递归方式求解,递归终止条件:当剩余需要匹配的字符串为空,剩余的字串不已要选的单词开头时,跳出
尝试写一下代码,TLE!
超时用例:
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaab"
["a","aa","aaa","aaaa","aaaaa","aaaaaa","aaaaaaa","aaaaaaaa","aaaaaaaaa","aaaaaaaaaa"]
可以发现存在大量的重复计算(匹配完”a”、“aa”和匹配完”aaa”,后面剩下的字符串都是一样的)
优化,加入记忆化,AC!
代码
python3
import functools
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
@functools.lru_cache(None)
def dfs(s):
if s == "":
return True
r = False
for w in wordDict:
if s.startswith(w):
r = r or dfs(s.replace(w,'',1))
return r
return dfs(s)
新思路
本题放在了,动态规划的类别当中。这种题一般递归方法是比较容易看出来的,递归中重复计算很多的情况,我们可以使用记忆化递归方式来优化
- 本题以dp的方式思考,
dp[i]表示\([0,i)\)这一段字符串是不是匹配的 - 对于
dp[j]来说,dp[j]的结果,就是:dp[j-1]的值与判断s[j-1,j]在不在words中dp[j-2]的值与判断s[j-2,j]在不在words中- …
- 以上的结果取
或,就是dp[j]的结果
- 我们发现
dp[j]只与前面求出的dp结果有关,与后面的内容无关 - Base Case 设置
dp[0]为True,有时候我们不能太纠结dp的BaseCase,有时候的BaseCase纯粹是为了满足通项时,理解起来可能会有点困难。这边我们空字符串我们认为匹配任意word都能成功
尝试使用动态规划写一下代码,AC!
代码
python3
class Solution:
def wordBreak(self, s: str, wordDict: List[str]) -> bool:
dp = [False for _ in range(len(s)+1)]
dp[0] = True
for i in range(len(s)+1):
for j in range(0, i):
w = s[j:i]
if (dp[j] and (w in wordDict)):
dp[i] = True
return dp[-1]